While Vision-Language-Action (VLA) models generalize well to generic instructions, they struggle with personalized commands such as "bring my cup," where the robot must act on one specific instance among visually similar objects.
We study this setting of manipulating personal objects, in which a VLA must identify and control a user-specific object unseen during training using only a few reference images.
To address this challenge, we propose Visual Attentive Prompting (VAP), a simple-yet-effective training-free perceptual adapter that equips frozen VLAs with top-down selective attention.
VAP treats the reference images as a non-parametric visual memory, grounds the personal object in the scene through open-vocabulary detection and embedding-based matching, and then injects this grounding as a visual prompt by highlighting the object and rewriting the instruction.
We construct two simulation benchmarks, Personalized-SIMPLER and Personalized-VLABench, and a real-world tabletop benchmark to evaluate personalized manipulation across multiple robots and tasks.
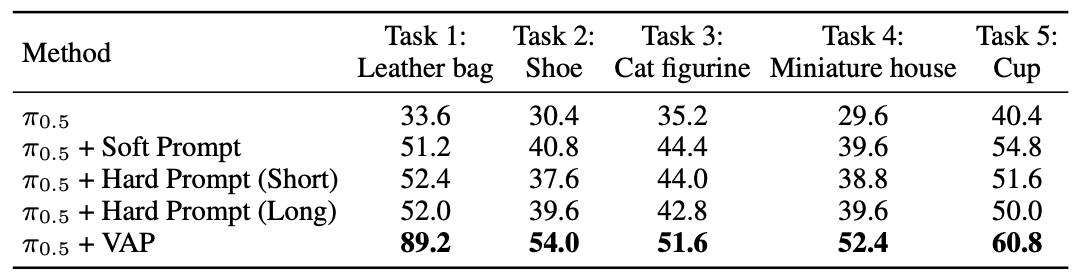
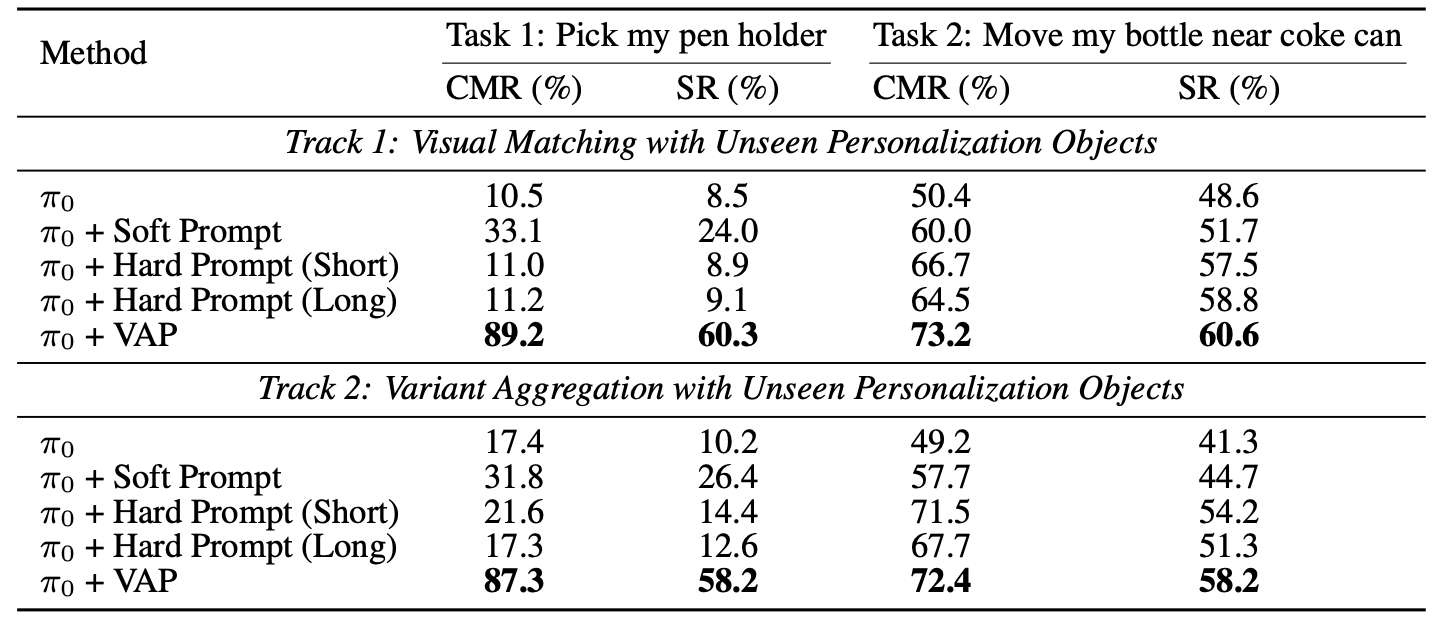
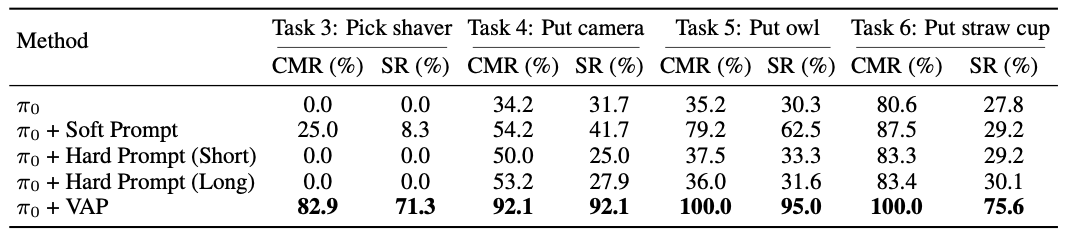
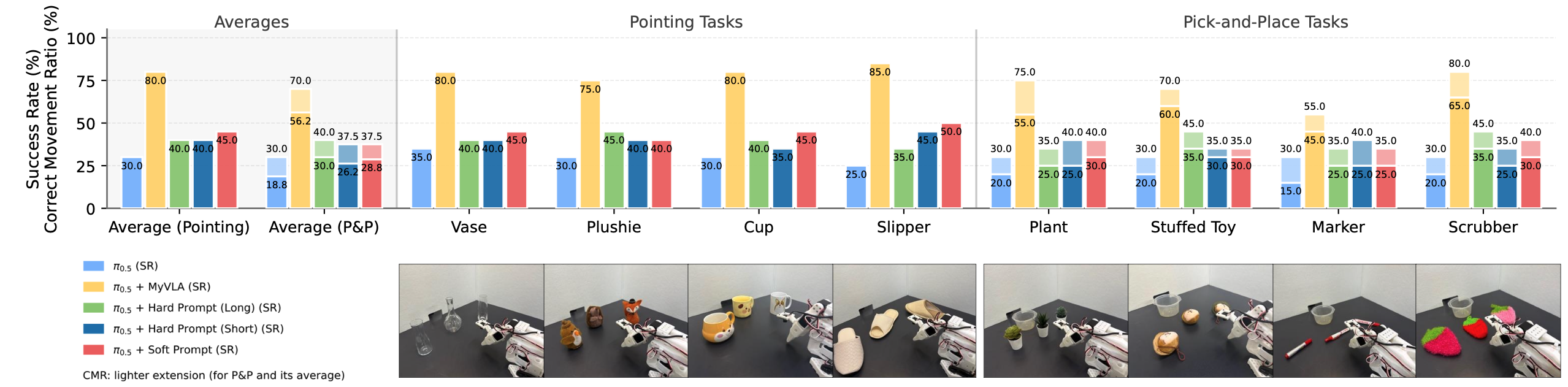
Experiments show that VAP consistently outperforms generic policies and token-learning baselines in both success rate and correct-object manipulation, helping to bridge the gap between semantic understanding and instance-level control.